Z Google BigQuery mam szczęście pracować od prawie dekady co pozwoliło mi dość szybko, jak na rynek Polski, zaznajomić się z korzyściami płynącymi z tworzenia nowoczesnego stacku analitycznego przy pomocy chmury Google oraz hurtowni danych leżącej w samym jej sercu.
Jak na klasyczną hurtownię danych przystało podstawowymi jej zadaniami są przechowywanie danych oraz umożliwianie ich dalszego wykorzystywania w celach biznesowych.
W pierwszej części napiszę więc na temat tego jakie są różne formy przechowywania tych danych oraz czym one różnią się od siebie.
Opiszę więc tabele, widoki, zmaterializowane widoki oraz funkcje i procedury ułatwiające pracę na ogromnych zapytaniach SQL.
Tabele są nieodłączną cechą platformy BigQuery, która zapewnia przewagę nad tradycyjnymi bazami danych.
Istnieje wiele różnych sposobów na utworzenie tabeli w BQ a ja przedstawię Ci dzisiaj kilka najprostszych.
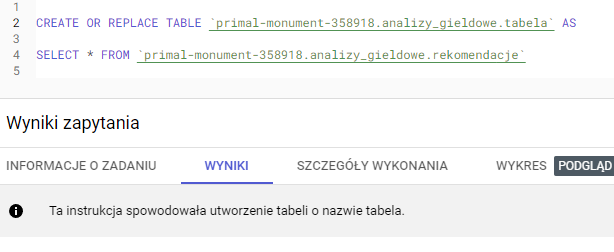
Prostym sposobem na stworzenie tabeli w BigQuery jest użycie instrukcji DDL (Data Definition Language) , jak poniżej:
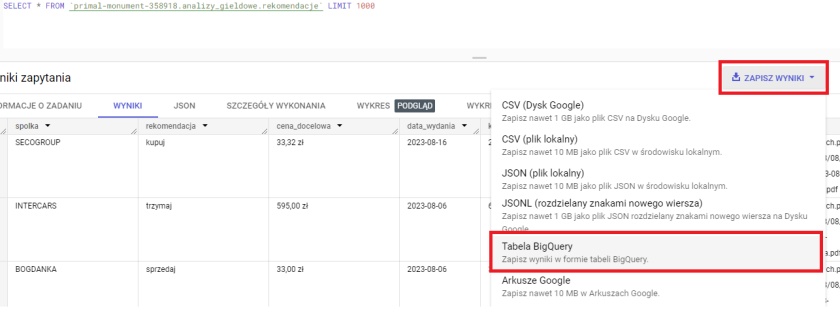
Innym sposobem na utworzenie tabeli w podobny sposób, ale przy użyciu bardziej GUI niż wyłącznie kodu, jest użycie wyników zapytania. Wystarczy uruchomić instrukcję SELECT, a następnie wykonać SAVE RESULTS → BigQuery Table.
Tabelę w BiGQuery stworzyć również możesz bezpośrednio przy pomocy Cloud Shell.
Po zalogowaniu do Cloud Shell skorzystaj z poniższej komendy edytując swoje parametry projektu i datasetu.
Nie są one fizycznymi tabelami i nie przechowują żadnych danych a co za tym idzie nie generują kosztów.
Zamiast tego odwołują się do danych przechowywanych w innych tabelach. Wspaniałą cechą widoków jest to, że po utworzeniu widoku można nadal wykonywać zapytania do widoku w taki sam sposób, jak do tabeli.
Niektóre z dodatkowych cech widoków to:
W przeciwieństwie do tabel, widoki są często tworzone, aby służyć bardziej konkretnym celom, takim jak ograniczenie dostępu użytkowników do danych lub segmentacja złożonych zapytań. Dobrze zaprojektowana hurtownia danych wykorzystuje widoki we właściwym miejscu i czasie.
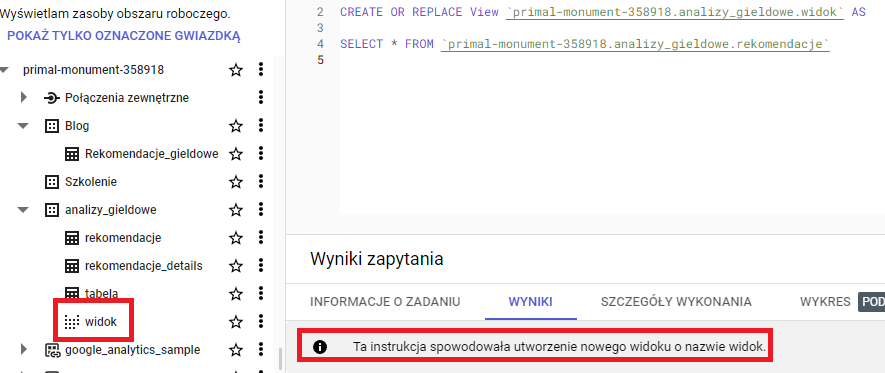
Podobnie jak w przypadku tabel najczęstszym sposobem tworzenia widoku w zbiorze danych jest instrukcja DDL – CREATE VIEW
Widoki od tabel odróżnisz ich graficzną reprezentacją w interfejsie, dzięki czemu od razu będziesz wiedział czy pracujesz na tabeli czy widoku.
Przechowuje wyniki zapytania SQL jako strukturę podobną do tabeli w BigQuery, podobnie jak tabela przechowuje dane.
Jednak w przeciwieństwie do zwykłej tabeli, widoki zmaterializowane automatycznie aktualizują przechowywane dane wynikowe po zaktualizowaniu tabel bazowych w czasie rzeczywistym, bez konieczności ponownego uruchamiania zapytania.
Widok zmaterializowany można porównać do migawki wyniku zapytania, zapisywanej jako tabela i aktualizowanej za każdym razem, gdy dane bazowe są aktualizowane.
Może to być bardzo pomocne w przypadku dużych zestawów danych lub zapytań, których uruchomienie zajmuje dużo czasu, ponieważ można je wstępnie obliczyć w widoku zmaterializowanym, aby uzyskać do nich szybki dostęp.
Poniżej znajdziesz kilka podstawowych cech widoków zmaterializowanych w BigQuery:
Zasadniczo, widoki zmaterializowane oferują niskie lub zerowe koszty utrzymania i zwracają świeże dane za każdym razem i przy każdym zapytaniu, niezależnie od tego, jak niedawno zaktualizowano tabele bazowe.
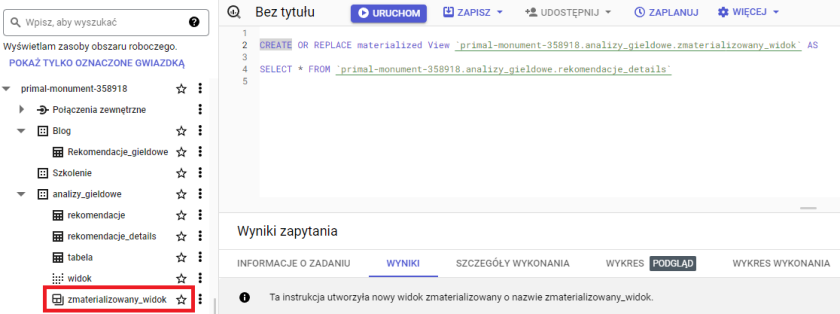
Zmaterializowany widok tworzymy tak samo jak widok przy pomocy operacji DDL dodając słowo materialized przed słowem view.
Umożliwiają one napisanie fragmentu kodu wielokrotnego użytku, który można wywołać z dowolnego miejsca w zapytaniu.
Procedur składowanych można używać do obsługi złożonych procesów ETL, wykonywania wywołań API i przeprowadzania walidacji danych.
Jeśli korzystasz z Pythona lub znasz dowolny język programowania, możesz myśleć o nich jako o funkcjach zdefiniowanych przez użytkownika, w których możesz podać niestandardowe parametry, aby zwrócić żądane dane wyjściowe.
W podobny sposób procedury składowane mają następujące cechy:
Jak zapewne sobie wyobrażacie przypadki ich zastosowania są niezliczone.
Poniżej napiszę kilka z nich tak aby rozjaśnić Ci w jakich sytuacjach warto po nie sięgnąć.
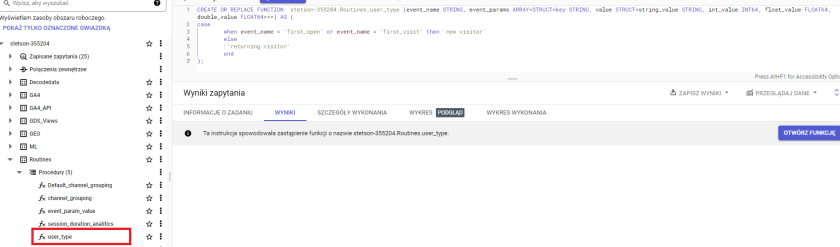
Z pomocą znowu przyjdzie nam komenda DDL : Create or replace.
W tym przypadku wpisujemy Create or replace function a następnie w nawiasie podajemy jej parametry. Po fragmencie tekstu AS w nawiasie opisujemy co funkcja ma robić.
Poniżej przykład, w którym raz napisany CASE może być później łatwo stosowany we wszystkich naszych zapytaniach co oszczędza nam sporo czasu podczas codziennej pracy.