Replikacja danych do BigQuery – Jedyny przewodnik po procesach ETL i ELT w GCP jakiego potrzebujesz
Co najfajniejsze, każdy z was może z niego skorzystać bez żadnych opłat licencyjnych. Samo narzędzie nie tylko świetnie nadaje się dla małych biznesów ale przede wszystkim ogromnych korporacji.
Aby cieszyć się jednak w pełni z jego zalet i móc przeprowadzać nasze zadania analityczne na danych, musimy w pierwszej kolejności skonfigurować procesy replikacji z naszych oryginalnych źródeł danych do tabel i zbiorów danych w naszej hurtowni.
W praktyce wygląda to tak, że nawet małe firmy nierzadko swoje dane przechowują w różnych źródłach. I nie byłoby z tym nic złego gdyby nie fakt, że są to na tyle różne struktury i typy danych, że nie istnieje jedno rozwiązanie, którego moglibyśmy z sukcesem i małymi kosztami użyć do tworzenia procesów ETL.
Ten przewodnik powstał po to abyś nie musiał się więcej zastanawiać jakiego konkretnie narzędzia dostępnego w GCP powinieneś użyć aby móc replikować dane do hurtowni uwzględniając koszt jego utrzymania, poziom trudności implementacji oraz czas potrzebny na jego wdrożenie.
Proces ETL (z angielskiego Extract, Transform and Load) jest to proces polegający na pobraniu danych ze źródła, transformacji i załadowaniu ich do celu, jakim jest w naszym przypadku hurtownia danych.
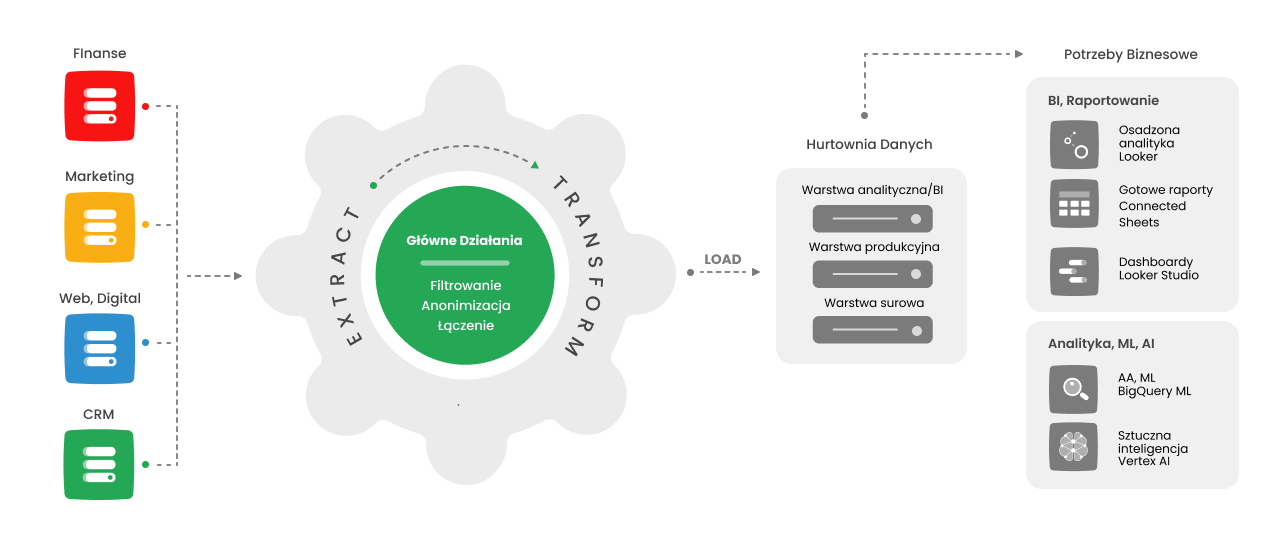
Proces ELT (Extract, Load, Transform) różni się tym, że transformację robimy już po załadowaniu naszych danych do hurtowni danych.
Odwrotny proces ETL polegać będzie natomiast na przekazaniu danych z hurtowni danych z powrotem do źródła (np. po uprzednim wzbogaceniu ich innymi danymi lub wynikami modeli analitycznych).
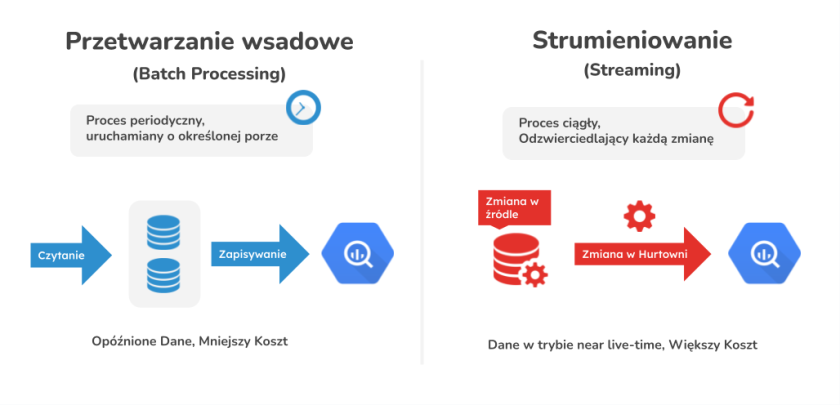
Procesy replikacyjne do BigQuery mogą przybrać dwie formy – strumieniowania (tzw. streaming) danych oraz przetwarzania wsadowego (tzw. batch processing).
Przetwarzanie wsadowe dla odmiany uruchomi się automatycznie o określonej porze i nadpisze bądź doda nowe dane do Twoich tabel.
Zaletą strumieniowania jest to, że masz praktycznie ciągły dostęp do tych samych danych, które są w tabelach źródłowych, wadą natomiast jest fakt, że musisz za taki proces więcej zapłacić w GCP.
Ponieważ przetwarzanie wsadowe jest darmowe idealnie się nada w sytuacjach kiedy możesz je zaplanować na jakąś konkretną godzinę tak aby Twoi menedżerowie mieli zawsze dostęp do danych podsumowujących np. wczorajszy dzień.
Do hurtowni danych możemy utworzyć procesy replikacyjne z wielu różnych rodzajów źródeł. Aby dobrze zrozumieć, jakiej technologii będziemy używać do utworzenia procesu ETL najpierw przybliżę wam rodzaje najpopularniejszych źródeł danych oraz ich charakterystykę.

Pliki AVRO, ORC oraz Parquet
Plik te to najoptymalniejsza forma do przechowywania i wymiany danych w BIgQuery. Są kompaktowe i wydajne, dzięki czemu są idealne do przechowywania dużych zbiorów danych.
Są oparte na schematach, które definiują strukturę danych. Schemat może być określony w pliku tekstowym lub wewnątrz pliku. Schemat pozwala na łatwe odczytanie i zapisanie danych z tego typu plików.
Poniżej zebrałem kilka najważniejszych cech tych plików
{
"name": "Janek Kowalski",
"age": 30,
"city": "Warszawa"
}
{
"name": "Janina Kowalska",
"age": 25,
"city": "Poznań"
}
name,age,city
John Doe,30,London
Jane Doe,25,New York
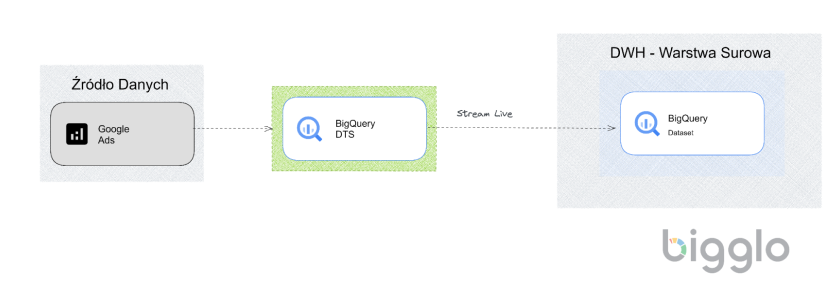
Jako, że źródła danych Google mają w większości bardzo uproszczony proces replikacji do hurtowni danych BigQuery stworzę z tego oddzielną kategorię i pokażę Ci jak w prosty sposób bardzo szybko zacząć replikować dane do BigQuery z Google Analytics, Google Ads, Google Campaign Manager, Google Ads Manager, Google Play, Google Merchant Center, Youtube, Firebase czy Google Ads 360.
Osobiście uważam, że możliwość ładowania danych z najpopularniejszych programów Google, z których korzystacie na co dzień czyni BigQuery fenomenalnym narzędziem szczególnie dla działów marketingu, promocji i sprzedaży, które korzystają z nich na co dzień.
W ciągu ostatnich kilku lat Google Cloud znacznie zwiększył ilośc techhnologii natywnych umożliwiających tworzenie procesów replikacyjnych. Jeszcze kilka lat temu zmuszeni byliśmy używać zaledwie trzech technologii natywnych. Dzisiaj lista jest dość długa, a większość technologii jest usprawniania na bieżąco. To pozwala optymalizować czas potrzebny na wdrożenie jak i również zmniejszyć koszt utrzymania.
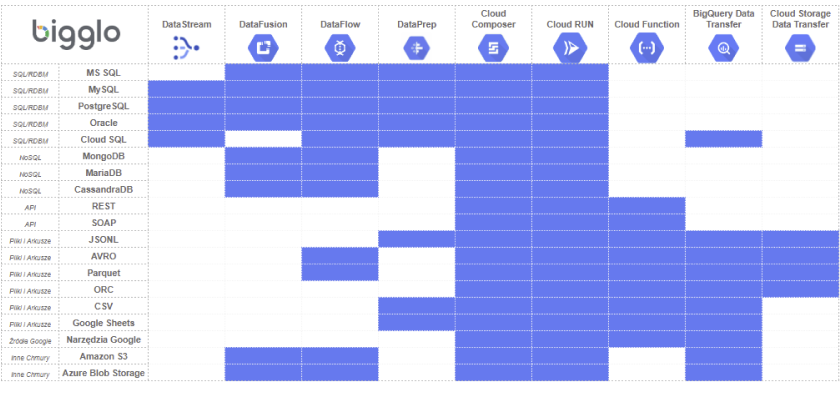
Stworzyłem również macierz ukazującą, których z tych technologii możecie użyć w zależności od źródła przetrzymywania waszych danych.
Jak widzicie są na tej liście narzędzia, które w teorii pomogą wam stworzyć proces ETL z każdego źródła. Pisze tutaj o Cloud Composer oraz Cloud RUN. Należy jednak dodać, że nie są to technologie przeznaczone do ich tworzenia a technologie, które mogą pomóc je przeprowadzić i zautomatyzować.
Wybierając odpowiednią technologię powinniśmy wziąć pod uwagę kilka dodatkowych czynników.
Wspomniane wyżej technologie są mocno oparte na programowaniu.
W innych scenariuszach zbawienne będą rozwiązania, które możemy “wyklikać” z interaktywnego GUI bez znajomości Pythona, JavaScript czy GO, i których utrzymanie będzie mniej pracochłonne.
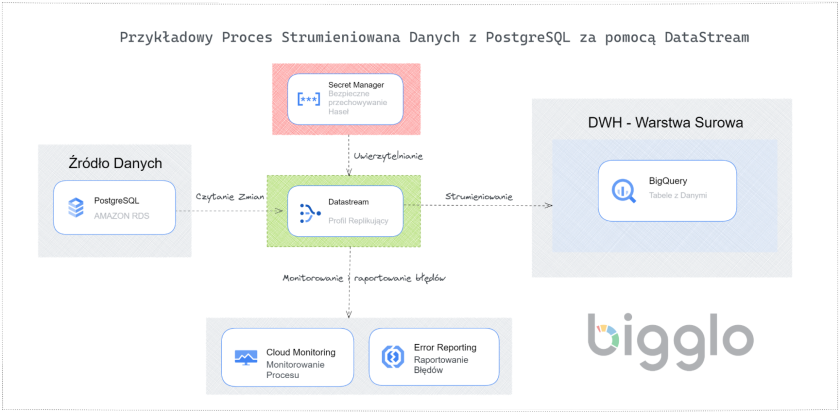
DataStream jest natywnym narzędziem Google Cloud umożliwiającym replikowanie danych z relacyjnych baz danych SQL od najpopularniejszych dostawców takich jak MySQL, PostgreSQL, Oracle, Cloud SQL czy AlloyDB.
Jest oparty na technologii CDC (Change Data Capture), która odzwierciedla wszystkie operacje typu DML (Data Manipulation Language) w Twojej bazie danych.
Dla przykładu, jeśli w Twoim źródle została przeprowadzona operacja UPDATE na konkretnym wierszu – Datastream odzwierciedla ją w Twojej hurtowni danych.
Takie podejście gwarantuje, że zawsze operujesz na świeżych danych.
DataStream jest również prosty w konfiguracji. Jedyne czego będziesz potrzebować to przygotowanie Twojej bazy danych do możliwości konfiguracji procesów CDC.
Poniżej znajduje się przykładowy scenariusz utworzenia takiego procesu replikacyjnego z bazy danych typu PostgreSQL za pomocą DataStream.
DataFusion to natywna dla Google Cloud usługa integracji danych, która oferuje wizualny interfejs typu „wskaż i kliknij” do wdrażania procesów ETL, eksploracji, transformacji danych oraz zarządzania metadanymi.

Dodać należy, że jest to tylko koszt związany z instancją. Do tego musimy doliczyć koszt związany z przetwarzaniem naszych danych za pomocą Dataproc oraz kosztami strumieniowania danych.
DataFusion nie będzie więc optymalnym narzędziem, jeśli wasze potrzeby replikacyjne są niewielkie i zakładacie scenariusz, w którym transformację danych robicie już bezpośrednio w hurtowni danych . Jego prawdziwa potęga zdaje się być zauważalna dopiero przy większych organizacjach z wielkimi potrzebami replikacyjnymi.
Cloud Composer jest w pełni zarządzaną usługą umożliwiającą orkiestrację zadań i procesów w chmurze Google. I jeśli powyższe zdanie Ci nic nie mówi najprawdopodobniej nie będziesz mógł z niego skorzystać bez pomocy doświadczonego inżyniera danych z dobrą znajomością języka Python oraz Apache Airflow, na bazie którego Cloud Composer został stworzony.
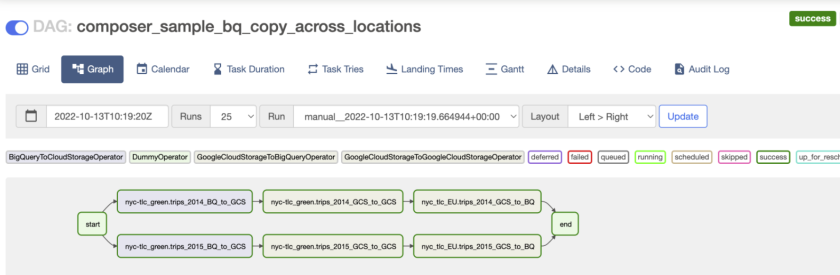
DataFlow jest bezserwerową, szybką i efektywną kosztowo usługą umożliwiającą tworzenie i zarządzanie ogromnymi przepływami danych w Twoim środowisku Google Cloud. DataFlow umożliwi Ci tworzenie procesów ELT i ETL zarówno opartych na strumieniowaniu danych jak i przetwarzaniu wsadowym.


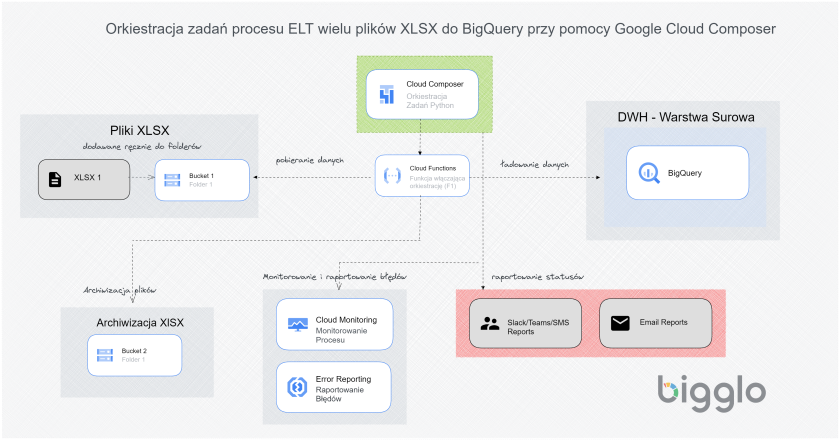
DataPrep to narzędzie oryginalnie stworzone przez firmę Trifacta, a później wykupione przez Google i dodane jako jedna z technologii Google Cloud w module analitycznym.
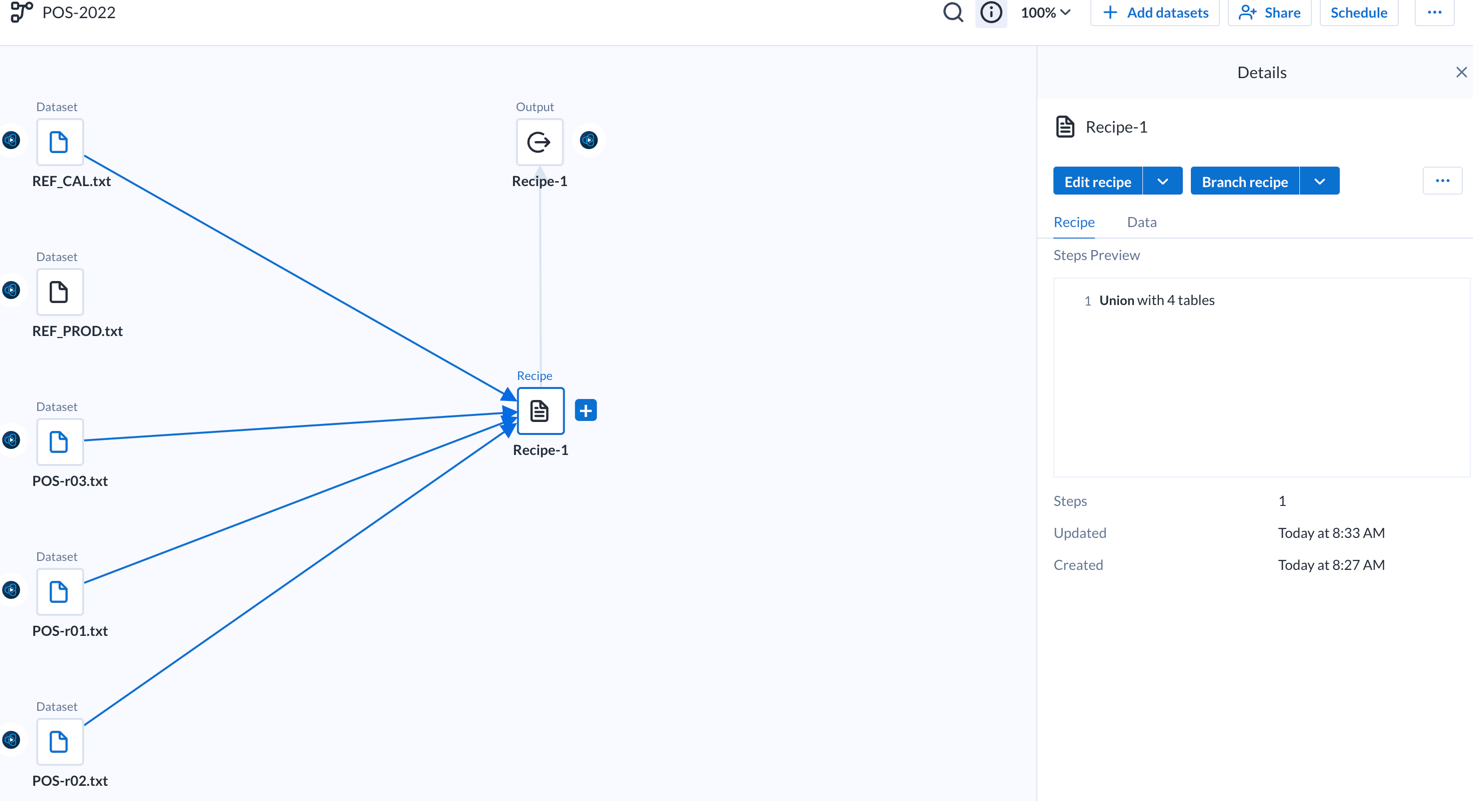
Do wad możemy zaliczyć fakt, że nie stworzymy procesu replikacyjnego bez umiejętności programistycznych. Aby zaplanować automatyczne uruchamianie procesu ELT stworzonego przy pomocy Cloud RUN będziemy potrzebowali skorzystać z innych funkcji GCP takich jak, Cloud Scheduler, Cloud Workflows, Container Registry czy wspomniany wcześniej Eventarc co powoduje, że ta metoda nie będzie łatwo dostępna dla początkujących użytkowników GCP.
Google Analytics 4
Firebase
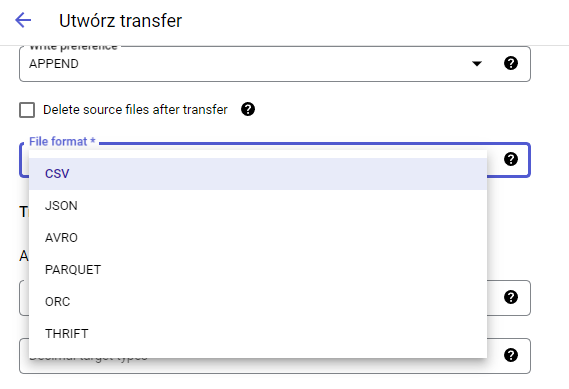
Transferować możemy dane z plików CSV,JSON,AVRO,ORC,PARQUET oraz THRIFT.
Dane możemy dodać do istniejącej już tabeli ( metodologią APPEND ) lub nadpisać jej całą zawartość ( metodologia MIRROR ). Tabela musi być uprzednio utworzona jeśli konfigurujemy proces transferu przy pomocy interfejsu GUI.
Jest wiele możliwości replikacji naszych danych do hurtowni. Powyższy przewodnik opisuje pokrótce tylko technologie natywne Google Cloud.
Pamiętajmy jednak, że skorzystać możemy również z wielu konektorów umożliwiających prosty i intuicyjny sposób replikacji danych bez żadnej wiedzy programistycznej. Kilka z nich jest dostępnych bezpośrednio w marketplace GCP.
Biorąc pod uwagę finalny wybór technologii, powinniśmy wziąć wiele czynników. Poniżej spisałem kilka z nich:
W Bigglo stworzyliśmy setki procesów replikacyjnych wykorzystując nie tylko narzędzia natywnej chmury obliczeniowej GCP ale również płatne konektory od innych dostawców.
Jeśli po przeczytaniu tego poradnika nadal masz wątpliwości jaki scenariusz wybrać dla siebie – umów się na darmową konsultację z naszym ekspertem, który pomoże wybrać dla Ciebie idealną ścieżkę replikacji Twoich danych.

Ustawienia plików cookies
Informacje o plikach cookies
Szanujemy Twoją prywatność