Co to jest RANK?
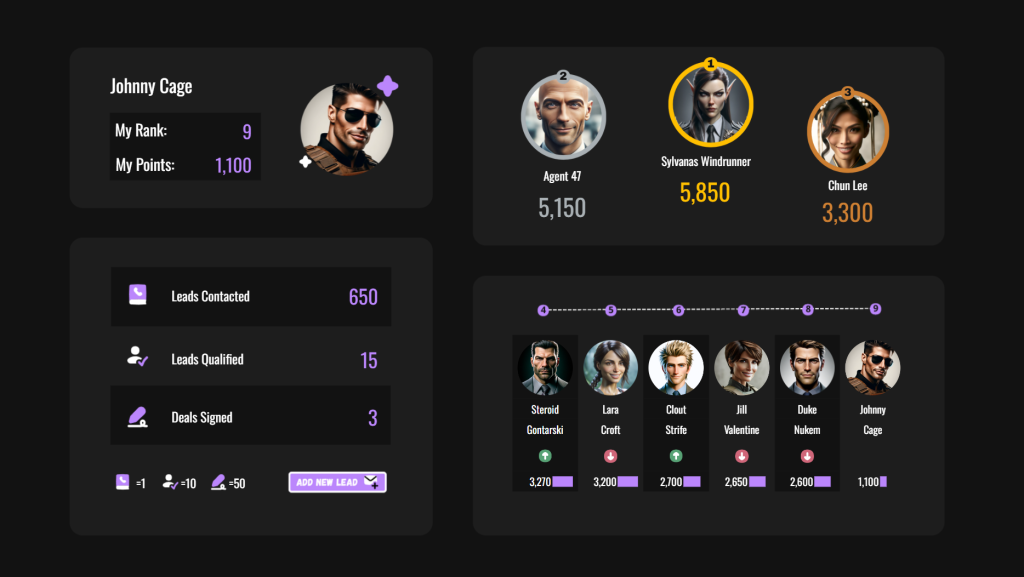
RANK to funkcja w SQL, która przypisuje rangę (pozycję) każdemu wierszowi w zestawie danych, w oparciu o określone kryteria sortowania. W BigQuery, RANK jest używana do generowania unikalnych rang, nawet jeśli wiele wierszy ma tę samą wartość. W przypadku powtarzających się wartości, funkcja RANK przypisuje tę samą rangę, a następnie pomija kolejne rangi.
Zastosowanie RANK
RANK w BigQuery ma wiele zastosowań:
- Identyfikacja najlepszych i najgorszych wyników: RANK pozwala na łatwe określenie, które wiersze w tabeli mają najwyższą lub najniższą wartość w danej kolumnie.
- Analiza trendów: RANK może być użyty do zidentyfikowania trendów w danych, np. poprzez określenie, które produkty mają najwyższą sprzedaż w danym okresie.
- Porównywanie danych: RANK pozwala na porównanie danych z różnych okresów lub grup, np. poprzez określenie, które produkty mają najwyższą sprzedaż w porównaniu do innych produktów.
- Filtrowanie danych: RANK może być użyty do filtrowania danych, np. poprzez wyświetlenie tylko 10 najlepszych produktów.
Przykład użycia w BigQuery
Załóżmy, że mamy tabelę o nazwie „produkty” z następującymi danymi:
| Produkt | Sprzedaż |
|---|---|
| Produkt A | 100 |
| Produkt B | 50 |
| Produkt C | 100 |
| Produkt D | 200 |
| Produkt E | 50 |
Aby wyświetlić ranking produktów według sprzedaży, możemy użyć następującego kodu SQL:
SELECT
Produkt,
Sprzedaż,
RANK() OVER (ORDER BY Sprzedaż DESC) AS Rank
FROM
`projekt.dataset.produkty`
ORDER BY
Rank;
Wynik tego zapytania będzie wyglądał następująco:
| Produkt | Sprzedaż | Rank |
|---|---|---|
| Produkt D | 200 | 1 |
| Produkt A | 100 | 2 |
| Produkt C | 100 | 2 |
| Produkt B | 50 | 4 |
| Produkt E | 50 | 4 |
Najczęstsze błędy i sposoby ich unikania
Najczęstsze błędy popełniane przy użyciu RANK w BigQuery to:
- Nieprawidłowe sortowanie: Jeśli dane nie są sortowane poprawnie, RANK może nie generować prawidłowych rang.
- Brak użycia klauzul PARTITION BY: Jeśli potrzebujesz generować rankingi w ramach różnych grup danych, musisz użyć klauzuli PARTITION BY.
- Nieprawidłowe użycie funkcji agregujących: RANK nie może być używany bezpośrednio w połączeniu z funkcjami agregującymi, takimi jak SUM lub AVG.
Aby uniknąć tych błędów, upewnij się, że:
- Sortowanie danych: Upewnij się, że dane są sortowane zgodnie z oczekiwaniami przed użyciem funkcji RANK.
- Użycie klauzuli PARTITION BY: Jeśli potrzebujesz generować rankingi w ramach różnych grup danych, użyj klauzuli PARTITION BY.
- Użycie funkcji agregujących: Jeśli potrzebujesz użyć funkcji agregujących, zastosuj je przed użyciem funkcji RANK.
Optymalizacje i najlepsze praktyki
Aby zoptymalizować zapytania z użyciem RANK w BigQuery, należy:
- Użycie indeksów: Indeksowanie kolumn używanych w klauzule ORDER BY może znacznie przyspieszyć wykonanie zapytania.
- Użycie klauzul LIMIT i OFFSET: Jeśli potrzebujesz tylko kilku najlepszych lub najgorszych wyników, użyj klauzuli LIMIT i OFFSET, aby ograniczyć liczbę wierszy zwracanych przez zapytanie.
- Użycie funkcji APPROX_QUANTILES: Jeśli potrzebujesz zidentyfikować rangi w oparciu o przybliżone wartości, użyj funkcji APPROX_QUANTILES.
Porównanie z innymi dialektami SQL
Funkcja RANK jest dostępna w większości dialektów SQL, w tym MySQL, PostgreSQL i Oracle. Jednak sposób jej użycia może się nieznacznie różnić w zależności od dialektu. Na przykład, w MySQL funkcja RANK jest dostępna jako część rozszerzenia Window Functions, podczas gdy w PostgreSQL jest dostępna jako wbudowana funkcja.